Multiple datasources - Route selections
I hope you enjoy every step so far. Until this point of our Langchain/RAG journey, we have managed to build a simple local application and a querry transformation assistant. But what happens when we have multiple data sources? How to define where our application will retrieve the required information from? The definition of this process, finding the correct road, or better let's say finding the correct route, is called Routing.
There are many ways to give directions in real life, this applies here as well! As we can see in the following image, there are two main categories of routing.
- Logical Routing: Let LLM choose a DB based on the question.
- Semantic Routing: Embed question and choose prompt based on similarity.
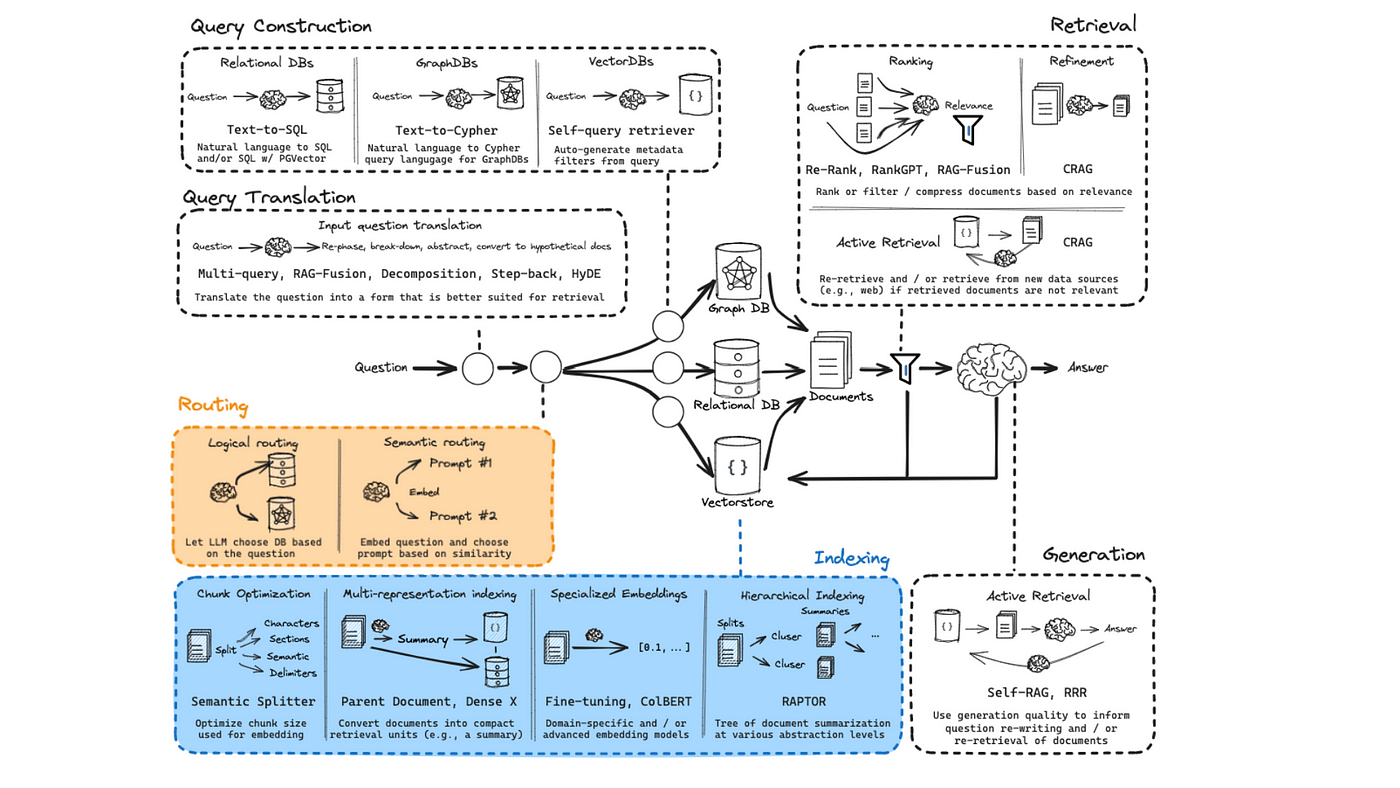
Before going though the architecture of such a RAG model for either Logical or Semantic routing, we are going to take a look at the differences accompanied with some simplier examples to understand which is best for your case case to go with.
Logical Routing
Routes are defined based on pre-determined rules, conditions, or algorithms. These rules are purely technical, and they don't take into account the meaning or context of the data. Logical Routing decisions are made based on factors like IP addresses, routing tables, or specific conditions that match certain criteria. It focuses on efficiently directing traffic or requests based on a logical or structural framework.
To put logical routing straight, imagine you’re in a city, and there are different routes based on traffic signals or road rules. These routes don't care about where you're coming from or your personal preferences, but simply about making sure traffic moves according to the road signs.
- Situation: You’re driving from Point A to Point B.
- Logical Rule: If a road is closed, take the next available road.
- Routing Decision: You don't think about why the road is closed; you just follow the detour and proceed based on traffic rules. It's like having a GPS system giving you orders, while driving, in a city that you have never been.
Semantic Routing
Routes are chosen based on the meaning or context of the data being transmitted. The logical routing decisions consider the content, purpose, or relationships within the data. It uses metadata or content analysis to decide the best route for a request, often ensuring that the most relevant resources handle the data. It prioritizes meaning and relevance to ensure that the request or data is handled in the best possible way based on its content.
Imagine you're in a library, and someone asks where to find a book. Instead of directing them based on just shelf numbers (logical), you direct them based on their interest in the content of the book. You ask, "What topic are you looking for?" and route them accordingly to the right section.
- Situation: You want to ask a question, but there are different people who can answer it.
- Semantic Rule: If your question is about science, you’re directed to a scientist; if it's about cooking, you’re directed to a chef.
- Routing Decision: The decision isn’t based on random criteria but on the meaning of your question and who’s best equipped to answer.
Based on Data/Context, Logical Routing ignores the meaning of the data and routes based on fixed rules while semantic routing analyzes the meaning and routes accordingly. Overall and while looking at the purpose, logical routing focuses on efficiency and technical structure and on the other hand, semantic routing focuses on relevance and meaningful processing.
Now that we got the main idea about what is the meaning of both, let us take a closer look to the code and how to build a system like that.
Initially, we need to call the modules that are going to help us accomplish our goal. I am not going to go through .env file again and won't be mentioning this file again in the future. Hopefully, you got the idea behind it, why it is important and the reasons I insist on using one. If you are not so sure on what file I am referring to, please take a look at the first two notebooks of this series and follow the steps to create one. Remember .env file will keep your Usernames, Passwords and Endpoint IDs safe without the need to erase them or hide them when sharing any file. So the modules we are going to use within this notebook are the following.
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import AzureOpenAIEmbeddings
# from langchain.chat_models import AzureChatOpenAI
from langchain_openai import AzureChatOpenAI
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from typing import Literal
from langchain.utils.math import cosine_similarity
from langchain.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
from dotenv import load_dotenv, dotenv_values
load_dotenv()
As we are using LLM models we need to define embeddings so that we can communicate with the computers and we "talk" the same language.
embeddings = AzureOpenAIEmbeddings(
deployment = os.getenv('OPENAI_DEPLOYMENT_NAME'),
model = os.getenv('OPENAI_MODEL_NAME_EMB'),
azure_endpoint = os.getenv('AZURE_OPENAI_ENDPOINT'),
openai_api_type = os.getenv('OPENAI_API_TYPE'),
)
Apart from that, vectorstore is essential as we need a place to store the vectors that will result from our embeddings call. Hecne, we are going to define a function call vectorstor_gen in order to store the information acquired (vectors generatated) from the files one owns and what to search from.
def vectorstore_gen(file, dir):
loader = PyPDFLoader(file)
documents = loader.load()
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=20)
text_chunks = text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(documents=text_chunks,
embedding=embeddings,
persist_directory=dir)
vectorstore.persist()
return vectorstore
Now image you have two documents or batter let's say two different files containing documents, and you want to create two vectorstore for both of them so that our llm will be able to choose betwen then and answer to your questions. Remember that we have created a folder data in our project and there we store all the data that we want to use for our RAG projects. In this example I am going to use dummy pdf names (A.pdf and B.pdf) and imaging that those two files contain information/documentation about different LLM models. Feel free to replace those with two irrelevant pdf files (when it comes to topic)
# Create a vectorestore to answer questions about topic A
vectorstore_A = vectorstore_gen('data/A.pdf', 'data/vectorstore_A')
# Create a vectorstore to answer questions about topic B
vectorstore_B = vectorstore_gen('data/B.pdf', 'data/vectorstore_B')
retriever_A = vectorstore_A.as_retriever(search_kwargs={'k':5})
retriever_B = vectorstore_B.as_retriever(search_kwargs={'k':5})
Now it is time to create the classes we are going to use to our routing models. Initially we are going to start with Logical Routing. Initially, we are going to build a class to route to the most relevant datasource accourding to the User's question. We are going to use an extention of BaseModel. The BaseModel class provides automatic validation parsing and serialization of data.
class QueryRouter(BaseModel):
"""Route a user query to the appropriate datasource that will help answer the query accurately"""
datasource: Literal['A', 'B', 'general'] = Field(..., description="Given a user question choose which datasource would be most relevant for answering their question")
question: str = Field(..., description="User question to be routed to the appropriate datasource")
Next we need to build and and call an LLM model that will help us build our RAG model, within which we are going to include routing stratey.
llm = AzureChatOpenAI(
deployment_name = os.getenv('LLM_35_Deployment'),
model_name = os.getenv('LLM_35_Model'),
azure_endpoint = os.getenv('AZURE_OPENAI_ENDPOINT'),
temperature = 0
)
structured_llm = llm.with_structured_output(QueryRouter, method="function_calling", include_raw=True)
structured_llm.invoke("Which datasource should be used for a question about general knowledge?")
Now it is time to build the routing prompt that will be included in the RAG pipeline. Not that if the pdf files that you include are not about a topic of NLP and/or LLMs pleas read the system prompt and change it accordingly
router_prompt = ChatPromptTemplate.from_messages(
[
("system",
"You are an expert router that can direct user queries to the appropriate datasource. Route the following user question about a topic in NLP and LLMs to the appropriate datasource.\nIf it is a general question not related to the provided datasources, route it to the general datasource.\n"),
("user", "{question}")
]
)
Finally we are ready to create the first router pipeline for our RAG model and include everythin we have been creating so far. Not that change the upcoming question accordingly.
router = (
{'question': RunnablePassthrough()}
| router_prompt
| structured_llm
)
question = "How does the A work?"
result = router.invoke(question)
result
result['parsed'].datasource.lower()
The final step is to define the a function that will choose which database should be used to answer our question, either A or B. In case you are running alongsite this project, the code chunks, and you have replaced A and B for example, (A could be vectore similiarity and B could be KAN Model) then you could repalce A and B in the following code chunk as well in order to obtain relevant answer/result.
qa_prompt = hub.pull('rlm/rag-prompt')
def choose_route(result):
llm_route = AzureChatOpenAI(
deployment_name = os.getenv('LLM_35_Deployment'),
model_name = os.getenv('LLM_35_Model'),
azure_endpoint = os.getenv('AZURE_OPENAI_ENDPOINT'),
temperature = 0
)
if "B" in result['parsed'].datasource.lower():
print(f"> Asking about B ...\nQuestion: {result['parsed'].question}\nAnswer:")
B_chain = (
{'context': retriever_B, 'question': RunnablePassthrough()}
| qa_prompt
| llm_route
| StrOutputParser()
)
return B_chain.invoke(result['parsed'].question)
elif "A" in result['parsed'].datasource.lower():
print(f"> Asking about A ...\nQuestion: {result['parsed'].question}\nAnswer:")
A_chain = (
{'context': retriever_lora, 'question': RunnablePassthrough()}
| qa_prompt
| llm_route
| StrOutputParser()
)
return A_chain.invoke(result['parsed'].question)
else:
print(f"> Asking about a general question ...\nQuestion: {result.question}\nAnswer:")
general_chain = llm_route | StrOutputParser()
return general_chain.invoke(result.question)
full_chain = router | RunnableLambda(choose_route)
full_chain.invoke("What is A?")
That concludes our example for logical routing. Next we are going to change a bit our previous coding chunks and produce an example about semantic routing. In this example we are going to create two templates about different topics. We are going to assume that the users ask questions about physics or mathematics. Initially we need to create two templates that are going to give a character to our LLM according to the question provided.
physical_template = """
You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{question}
"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{question}"""
The next step is to create a list containing the character templates. We are going to create embeddings about those routes in order to calculate the similarity with the question provided by the user. Remember that semantic routing checks the similarity of the meaning after all. The choice of the database that the RAG will provide the answer from is not defined by rules as the previous case.</p>
routes = [physical_template, math_template]
route_embeddings = embeddings.embed_documents(routes)
len(route_embeddings)
Now we can proceed to the definition of a function that according to the topic of the question that was provided, LLM will answer the question with a routing strategy to either physics or mathematics experties.
def router(input):
# Generate embeddings for the user query
query_embedding = embeddings.embed_query(input['question'])
# Getting similarity scores between the user query and the routes. This contains the similarity scores between the user query and each of the two routes.
similarity = cosine_similarity([query_embedding], route_embeddings)[0]
# Find the route that gives the maximum similarity score
route_id = similarity.argmax()
if route_id == 0:
print(f"> Asking a physics question ...\nQuestion: {input['question']}\nAnswer:")
else:
print(f"> Asking a math question ...\nQuestion: {input['question']}\nAnswer:")
return PromptTemplate.from_template(routes[route_id])
semantic_router_chain = (
{'question': RunnablePassthrough()}
| RunnableLambda(router)
| llm
| StrOutputParser
)
semantic_router_chain.invoke("What is the formula for the area of a circle?")
I hope you enjoyed this session as much as I did and a learned a thing or two. I wish that you kept a code chunk and will use it later on, on your own projects. Stay tuned for the next topic that we are going to take a look at this LangChain series
Be safe, code safer!
Subscribe to Kavour
Get the latest posts delivered right to your inbox

