Tülu 3 405B The New Heavyweight Champion in AI Models
Hold onto your hats, all of you people! The Allen Institute for AI has just unleashed Tülu 3 405B, a colossal 405-billion-parameter model that's not just flexing its muscles but also outpacing the competition. This update is setting new benchmarks, leaving rivals like DeepSeek V3 and GPT-4o in the dust, all while being as open-source as a community cookbook.
On January 30, 2025, the Allen Institute for AI (Ai2) proudly introduced Tülu 3 405B, marking the first time fully open post-training recipes have been applied to such a massive open-weight model. Building upon the success of their previous Tülu 3 release, this model demonstrates that size does matter, especially when combined with innovative training techniques. Tülu 3 405B doesn't just compete; it often surpasses models like DeepSeek V3 and GPT-4o, and leaves prior open-weight models, including Llama 3.1 405B Instruct and Nous Hermes 3 405B, eating its dust on many standard benchmarks.
So, how did Ai2 cook up this powerhouse? They scaled their proven Tülu 3 post-training recipe to the Llama-405B base model, following a five-step program:
- Data Delicacy: Carefully curating and synthesizing data targeting core skills.
- Supervised Finetuning (SFT): Applying a finely selected mix of prompts and their completions.
- Direct Preference Optimization (DPO): Tweaking the model based on both off- and on-policy preference data.
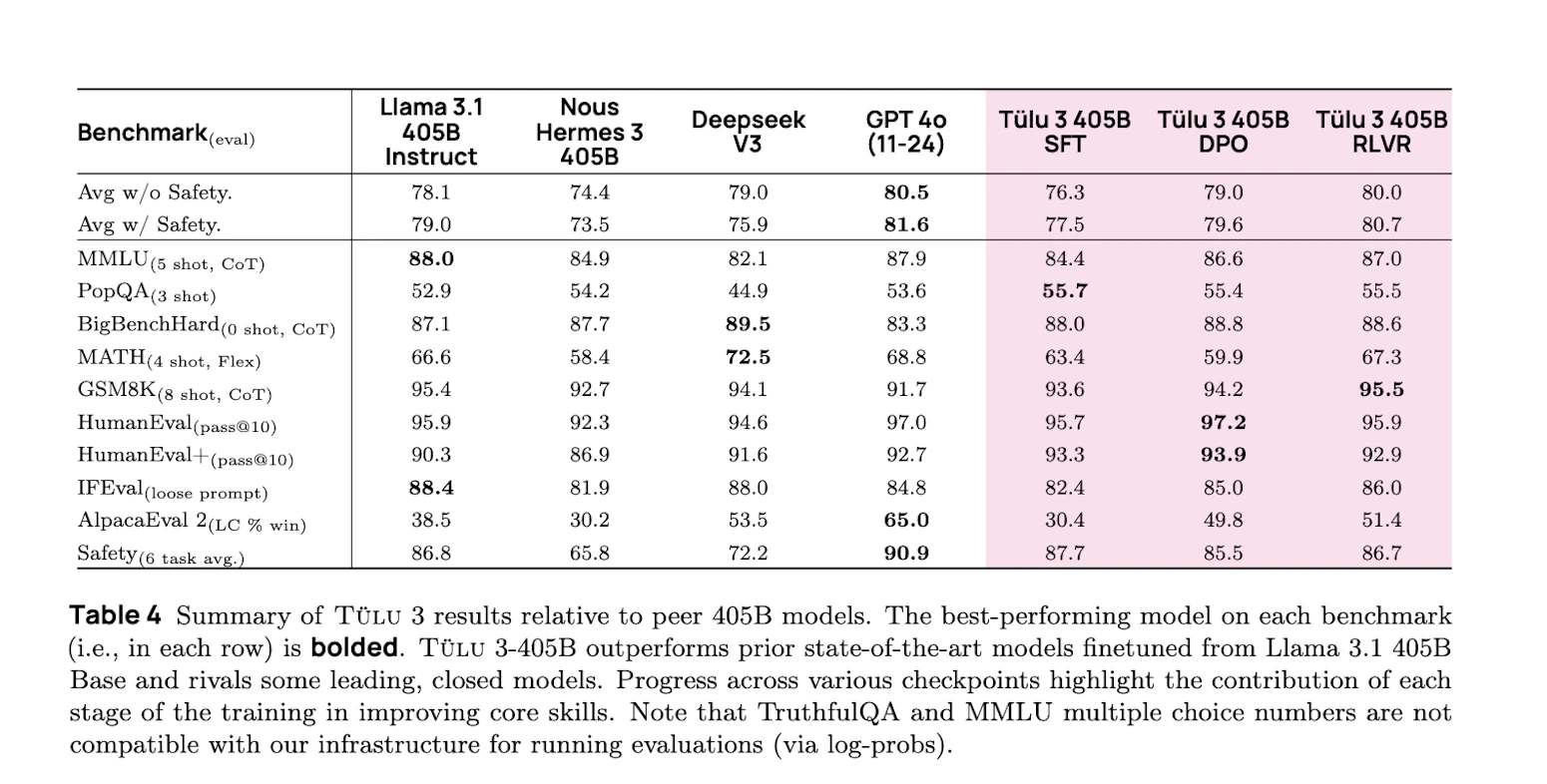
- Reinforcement Learning with Verifiable Rewards (RLVR): A fresh, RL-based method to boost specific skills with rewards you can take to the bank.
- Evaluation Extravaganza: Implementing a standardized suite for development, decontamination, and final evaluation stages.
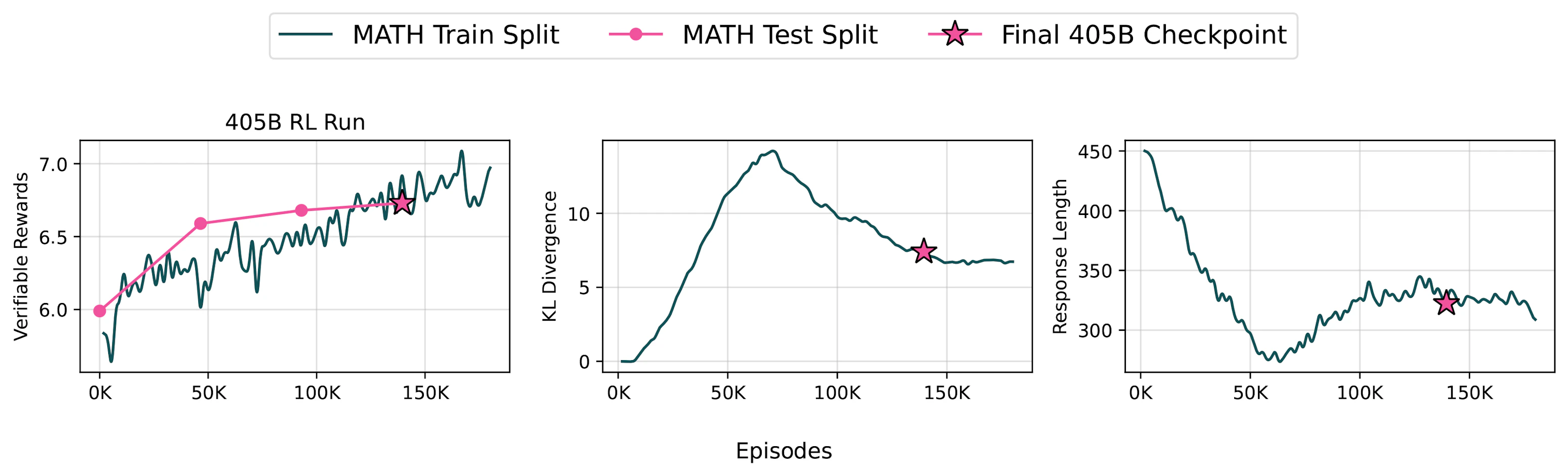
In the training arena, Ai2 employed their novel RLVR approach, focusing on tasks with clear-cut answers like math problems and precise instructions. To handle the 405B scale, they deployed the model using vLLM with 16-way tensor parallelism, utilizing 240 GPUs for training. Each RLVR iteration involved approximately 550 seconds for inference, 25 seconds for weight transfer, and 1500 seconds for training. Interestingly, they discovered that feeding the model exclusively MATH data, rather than a mix, yielded better results at this scale—a testament to the model's appetite for complex, specialized tasks.
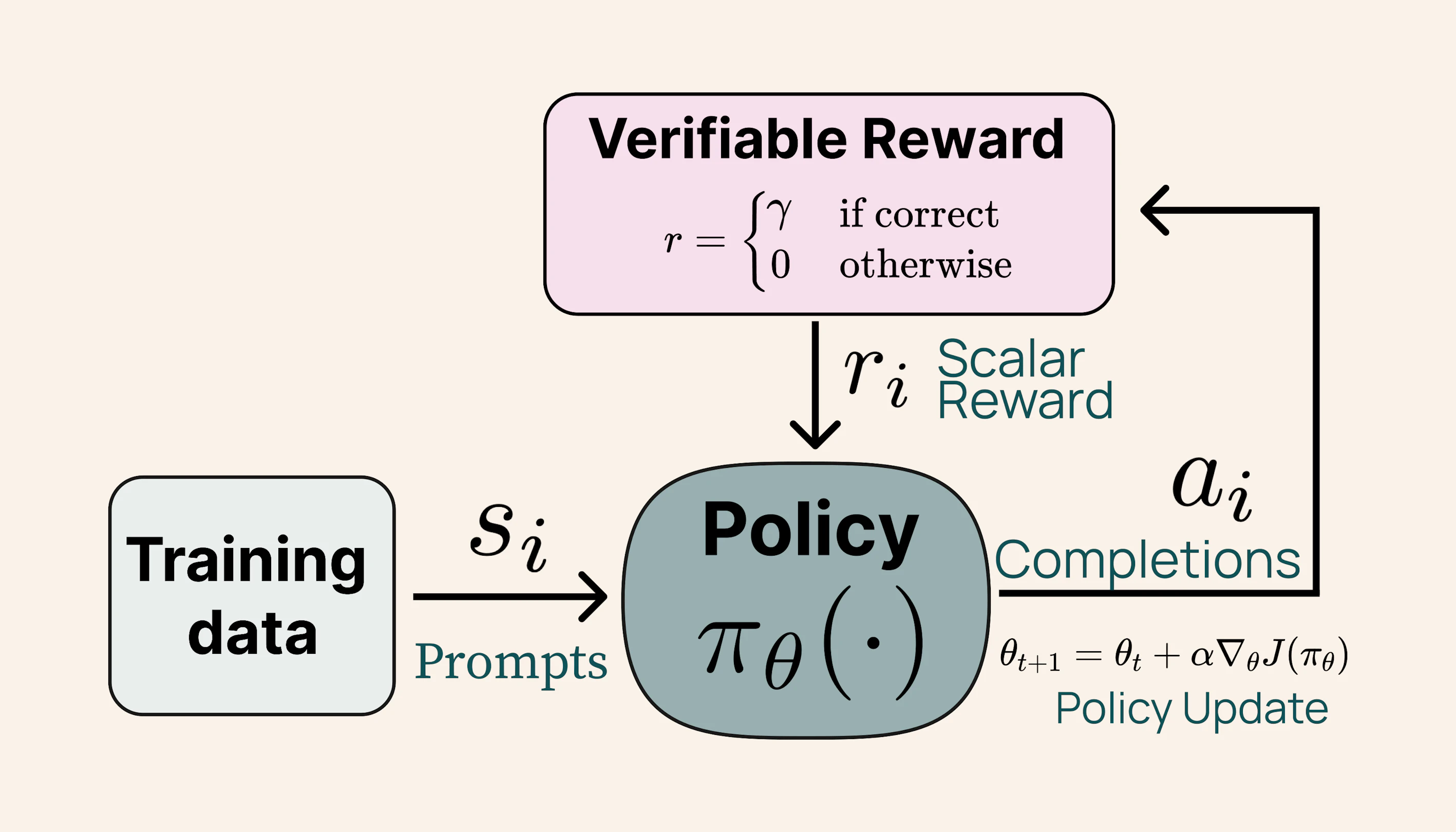
Tülu 3 405B isn't just big; it's a top performer. It achieves competitive or superior results compared to both DeepSeek V3 and GPT-4o, while also surpassing prior open-weight post-trained models of the same size on many standard benchmarks. Notably, the Reinforcement Learning from Verifiable Rewards (RLVR) framework improved MATH performance more significantly at this larger scale, echoing findings in the DeepSeek-R1 report. Overall, Tülu 3 405B shows a consistent edge over DeepSeek V3, especially when safety benchmarks are in play.
With Tülu 3 405B, Ai2 has not only scaled up their model parameters but also the impact of open-source AI. This release underscores the scalability and effectiveness of their post-training recipe at an unprecedented scale, setting a new standard in the AI community. As Tülu 3 405B continues to flex its capabilities, it's clear that the future of AI is not just about bigger models, but smarter, more open ones too. To get started and find out more detailes about the afforementioned updates you can visit official blog post.
Subscribe to Kavour
Get the latest posts delivered right to your inbox

