Enhancing retrieval augmented generation through drafting
In the evolving landscape of AI, large language models (LLMs) have become essential for generating human-like text. However, these models often struggle with accuracy, particularly when tasked with answering complex, knowledge-intensive questions. This challenge has given rise to Retrieval Augmented Generation (RAG) systems, which combine LLMs with external knowledge retrieval to improve the factual accuracy of responses. While RAG enhances accuracy, it comes with trade-offs in efficiency, especially when dealing with large amounts of retrieved data that require complex reasoning.
To address this, a novel framework called Speculative RAG has been introduced. This approach optimizes the balance between accuracy and efficiency by leveraging a two-step process: drafting and verification. The process begins with a smaller, specialized LLM—referred to as the RAG drafter—that generates multiple draft responses based on retrieved documents. These drafts are then fed into a larger, generalist LLM—acting as the verifier—to select the most accurate and contextually appropriate response.
Speculative RAG employs a technique known as speculative decoding, which speeds up the inference process by allowing the specialist LLM to generate multiple drafts simultaneously. This method not only reduces the computational load on the larger LLM but also ensures that the final output is both accurate and efficient.
For instance, when asked a question like "Which actress starred as Doralee Rhodes in the 1980 film Nine to Five?", the RAG system retrieves relevant documents from its knowledge base. The specialist drafter quickly generates several possible answers, each backed by its rationale. The generalist verifier then assesses these drafts, filtering out any inaccuracies—such as information mistakenly drawn from a related but incorrect source, like the Nine to Five musical—and selects the correct answer.
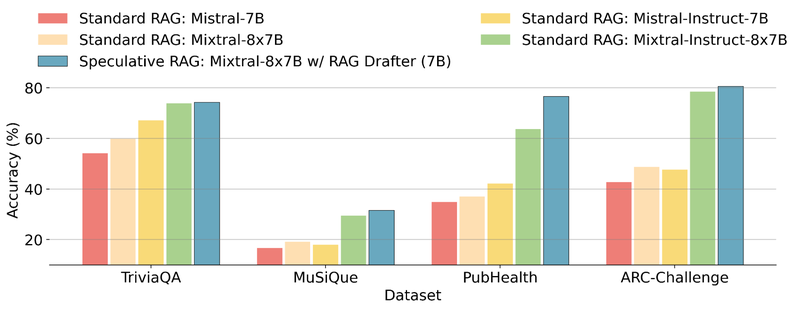
The effectiveness of Speculative RAG is demonstrated through rigorous benchmarking against standard RAG systems across datasets such as TriviaQA, MuSiQue, PubHealth, and ARC-Challenge. Results show that Speculative RAG not only achieves higher accuracy—outperforming traditional methods by up to 12.97% on some datasets—but also significantly reduces latency, cutting response times by as much as 51%. This dual improvement in both speed and accuracy represents a significant leap forward in the performance of RAG systems.
The success of Speculative RAG underscores the potential of collaborative AI architectures, where tasks are intelligently divided between specialized and generalist models. By offloading specific tasks to models optimized for those functions, Speculative RAG provides a robust framework for enhancing the quality of AI-generated content while maintaining efficiency. As AI continues to evolve, such innovations will be crucial in developing systems that are not only powerful but also reliable and quick, paving the way for more sophisticated and responsive AI applications.
You can read Google's research full blog post here or you can check our the official paper published related to the topic.
Subscribe to Kavour
Get the latest posts delivered right to your inbox

