Advancing Open Language Models by OlMo 2
The release of OLMo 2 marks a showcase on improved performance and stability through innovative training techniques and comprehensive evaluation frameworks.
Following the success of the first OLMo model released in February 2024, the Allen Institute for AI has intrduced OLMo 2, a new family of models that promise to narrow the performance gap between open and proprietary systems. This article delves into the features and innovations behind OLMo 2, highlighting its potential impact on the landscape of language modeling.
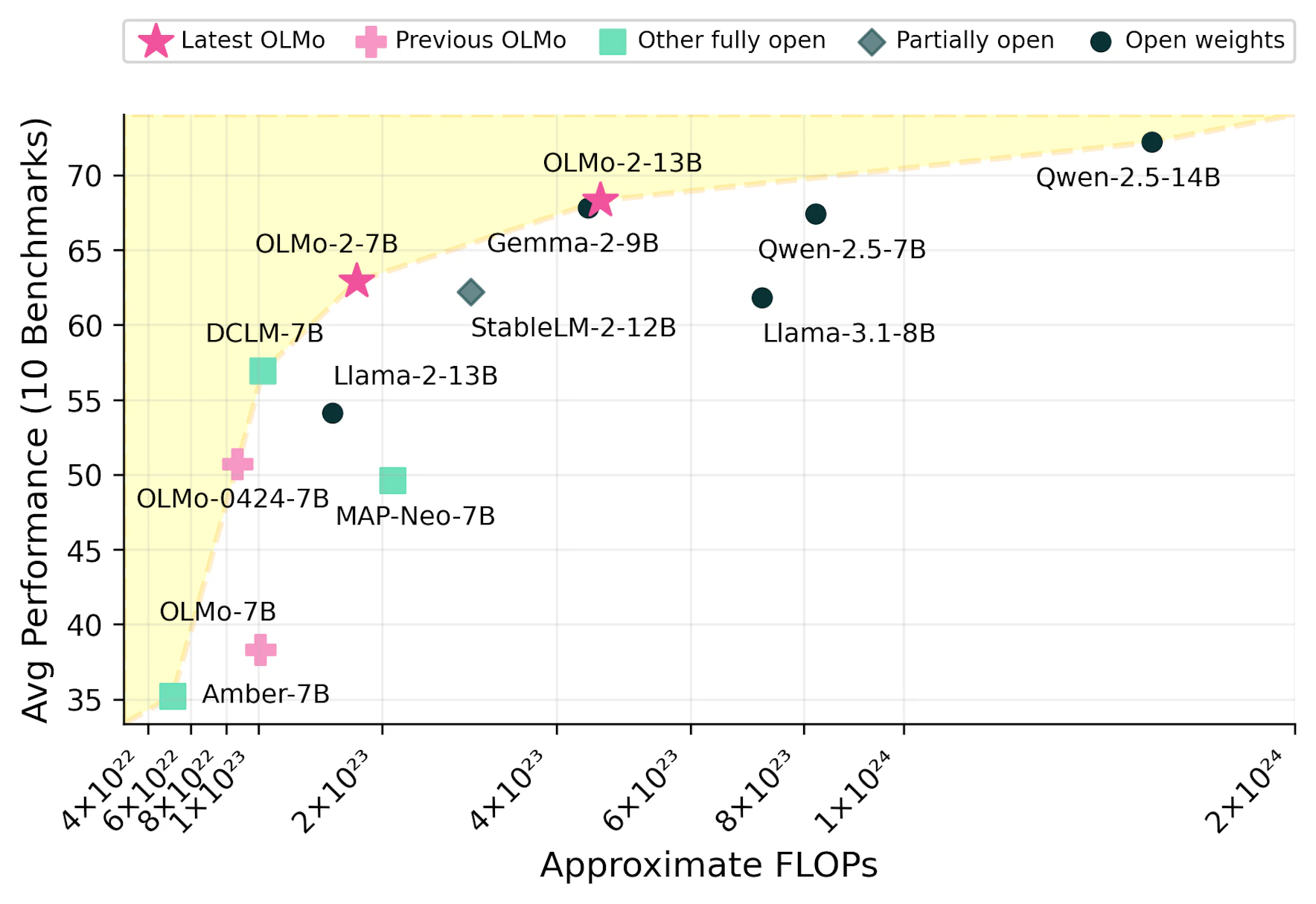
OLMo 2 includes two primary models: a 7 billion parameter model and a 13 billion parameter model, both trained on up to 5 trillion tokens. These models are designed to compete with leading open-weight models like Llama 3.1 on various English academic benchmarks. The development of OLMo 2 reflects a commitment to enhancing the capabilities of fully open models, providing researchers and developers with robust tools for natural language processing tasks.
A key aspect of OLMo 2's success lies in its innovative training techniques aimed at improving stability and performance:
- Training Stability: The team focused on enhancing long model training runs by addressing common issues such as loss spikes that can lead to lower final performance.
- Staged Training: This approach involves interventions during late pretraining to address knowledge gaps identified during earlier phases.
- Post-training Recipes: State-of-the-art post-training methodologies were applied to create instruction-tuned variants of OLMo 2, enhancing its capability to follow user instructions effectively.
The development team established the Open Language Modeling Evaluation System (OLMES), which consists of a suite of 20 evaluation benchmarks. This framework assesses core capabilities such as knowledge recall, commonsense reasoning, and mathematical problem-solving. By implementing OLMES, the team could track improvements throughout the development stages and ensure that OLMo 2 meets high-performance standards across various tasks.
The results from OLMo 2’s evaluations indicate that it outperforms many existing open-weight models. Notably, the OLMo 2 7B model surpassed the performance of Llama-3.1 8B on several benchmarks, while the OLMo 2 13B model outperformed Qwen 2.5 7B despite having lower total training FLOPs. These findings underscore OLMo 2's position at the Pareto frontier of training efficiency versus average performance.
The pretraining process for OLMo 2 was conducted in two stages:
- Stage One: Utilized a massive dataset called OLMo-Mix-1124, consisting of approximately 3.9 trillion tokens. The models were trained for one epoch on this dataset.
- Stage Two: Focused on high-quality web data and domain-specific content, resulting in an additional 843 billion tokens. This stage aimed to refine model capabilities further through targeted training.
The release also includes instruction-tuned variants known as OLMo 2-Instruct models. These variants were developed using advanced post-training techniques from Tülu 3, incorporating supervised finetuning and reinforcement learning methodologies. The results show that these models are competitive with other leading instruction-following models in the open-weight category.
The introduction of OLMo 2 represents a significant step forward in the open language model ecosystem. With its robust architecture, innovative training techniques, and comprehensive evaluation framework, OLMo 2 is positioned to empower researchers and developers in their pursuit of advanced natural language processing applications. As the community continues to engage with these developments, we can expect further enhancements in model performance and usability.
The advancements embodied in OLMo 2 highlight the potential for fully open language models to compete with proprietary systems effectively. By prioritizing transparency and collaboration within the AI community, Allen Institute for AI is paving the way for future innovations that will benefit researchers and practitioners alike. As we move forward, the lessons learned from developing OLMo 2 will undoubtedly influence subsequent generations of language models. If you feel like reading more and exploring this ai chapter, head here at the official blog post written by Allenai.
Subscribe to Kavour
Get the latest posts delivered right to your inbox

