NVIDIA Unveils Llama 3.1-Nemotron-51B
NVIDIA has introduced the Llama 3.1-Nemotron-51B language model, derived from Meta’s Llama-3.1-70B, showcasing superior accuracy and efficiency. This model leverages Neural Architecture Search (NAS) to balance performance with cost, making it accessible for diverse applications on a single NVIDIA H100 GPU.
NVIDIA's release of the Llama 3.1-Nemotron-51B marks a significant milestone in language model technology, blending cutting-edge efficiency with accuracy. This model, derived from Meta’s Llama-3.1-70B, is tailored using a novel Neural Architecture Search (NAS) approach that prioritizes workload efficiency and cost optimization. By fitting seamlessly on a single NVIDIA H100 GPU, it brings down the cost of running advanced AI models, opening new opportunities for both enterprises and developers.
Llama 3.1-Nemotron-51B-Instruct, developed using NAS and knowledge distillation techniques, delivers a groundbreaking balance between accuracy and cost-efficiency. While maintaining nearly the same accuracy as its reference model, Llama-3.1-70B, the Nemotron version achieves 2.2x faster inference. The model reduces the memory footprint and enables running 4x larger workloads on a single GPU, significantly enhancing throughput and reducing costs. Optimized for use in cloud, data centers, and edge devices, the model offers flexibility for various deployment scenarios, including Kubernetes and NIM blueprints.
On the positive side of things we can say that Nemotron-51B is:
- 2.2x faster inference compared to Llama-3.1-70B
- reduced memory footprint and FLOPs
- can run larger workloads on a single GPU
- superior cost-efficiency (accuracy per dollar)
- simplified deployment through NVIDIA NIM microservices
| Accuracy | Efficiency | |||
| MT Bench | MMLU | Text generation (128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-51B- Instruct | 8.99 | 80.2% | 6472 | 653 |
| Llama 3.1-70B- Instruct | 8.93 | 81.66% | 2975 | 339 |
| Llama 3.1-70B- Instruct (single GPU) | — | — | 1274 | 301 |
| Llama 3-70B | 8.94 | 80.17% | 2975 | 339 |
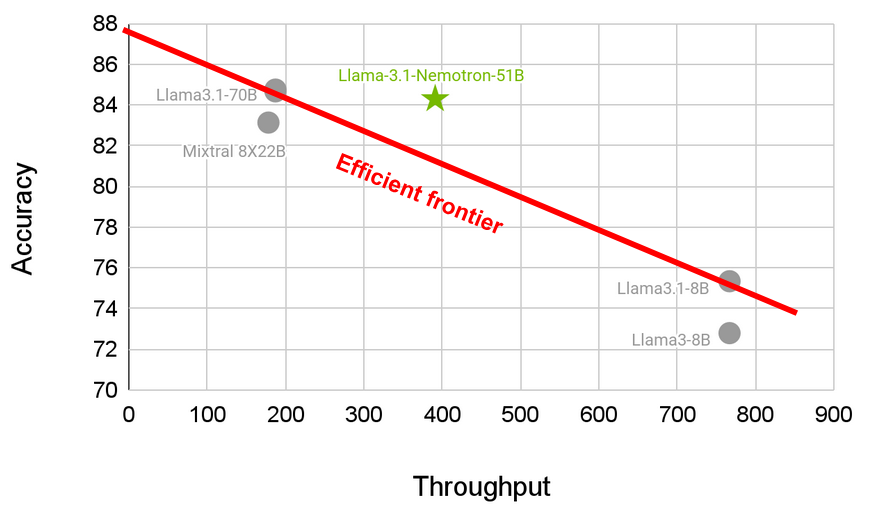
On the other hanb we can clearly see that there is:
- a slight accuracy tradeoff in favor of cost and efficiency
Some of the key features presented are the following:
- Neural Architecture Search (NAS): NAS allows the model to efficiently utilize a zoo of non-standard transformer blocks, optimizing for specific hardware constraints.
- Optimized for NVIDIA H100: The model fits on a single H100 GPU, making it accessible for high-demand workloads.
- Reduced Memory and FLOPs: The unique architecture reduces memory usage while maintaining competitive accuracy.
- High Throughput: The model supports larger batch sizes and delivers tokens per second efficiently, making it ideal for real-time applications.
- NIM Integration: Llama 3.1-Nemotron-51B is packaged as a microservice through NVIDIA NIM, simplifying the deployment process for developers.
The Llama 3.1-Nemotron-51B sets a new benchmark in the balance between efficiency and accuracy. By leveraging advanced Neural Architecture Search (NAS), NVIDIA has created a model that breaks the efficient frontier, delivering unparalleled performance at reduced costs. This model represents a significant leap forward for developers looking to deploy powerful AI models in real-world scenarios, offering an ideal tradeoff between performance and affordability. If interested and want to find out more, you can go to official blog post of NVIDIA.
Subscribe to Kavour
Get the latest posts delivered right to your inbox

